# BASIC TASKS
# HW1: Calculate the sum of data_basic
# HW2: Find the range (min and max) of data_basic
# HW3: Compute the variance of data_basic
# ADVANCED TASKS
# HW4: Calculate the standard deviation of mtcars$mpg
# HW5: Generate a summary of mtcars$hp (horsepower)
# BASIC TASKS
# HW1: Calculate the mean of data_numbers
# HW2: Find the median of data_numbers
# HW3: Write a function to compute the mode
# ADVANCED TASKS
# HW4: Compute the mean of iris$Sepal.Length
# HW5: Find the median of iris$Petal.Length grouped by Species
# BASIC TASKS
# HW1: Find the max and min of data_scores
# HW2: Calculate the 75th percentile of data_scores
# HW3: Compute the IQR of data_scores
# ADVANCED TASKS
# HW4: Find the 90th percentile of airquality$Temp
# HW5: Identify outliers in airquality$Ozone using IQR
# HW1: Calculate covariance between speed and distance
# HW2: Compute correlation between speed and distance
# HW3: Install the `moments` package and calculate skewness of speed
Plots visualize trends and relationships. Use plot() for basic graphs, lines()/points() for overlays, and par() for layouts. Customize with main, xlab, ylab, col, lwd, pch, and bg.
Demo Data (Basic)
# Simple dataset for beginners
x <- 1:10
y <- c(2, 4, 6, 8, 7, 5, 3, 1, 9, 10)
Demo Data (Advanced)
# Complex dataset: mtcars (built-in)
data(mtcars)
mpg <- mtcars$mpg # Miles per gallon
hp <- mtcars$hp # Horsepower
wt <- mtcars$wt # Weight
Practice
# BASIC TASKS
# HW1: Plot x vs. y as points
# HW2: Add a blue line to the plot
# HW3: Create a plot with red triangles (pch=17)
# ADVANCED TASKS
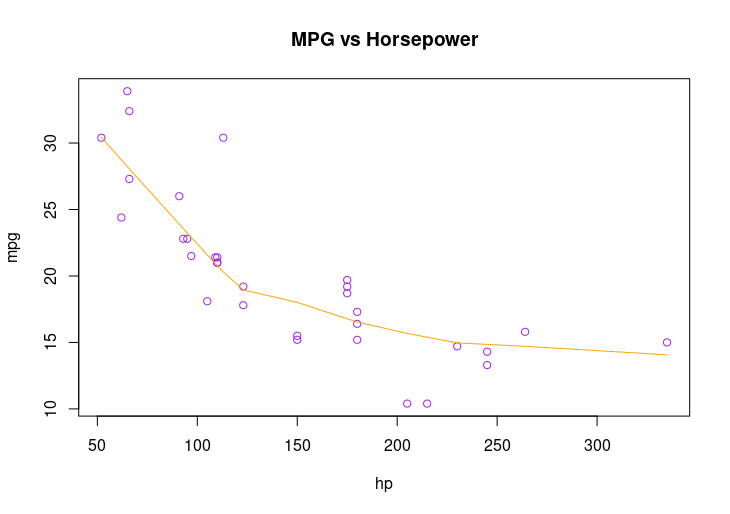
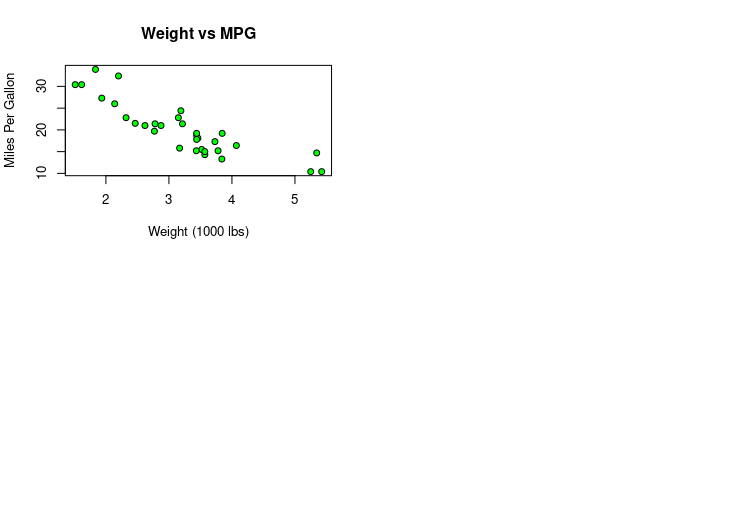
# HW4: Plot mpg vs. hp from mtcars, add a smooth line
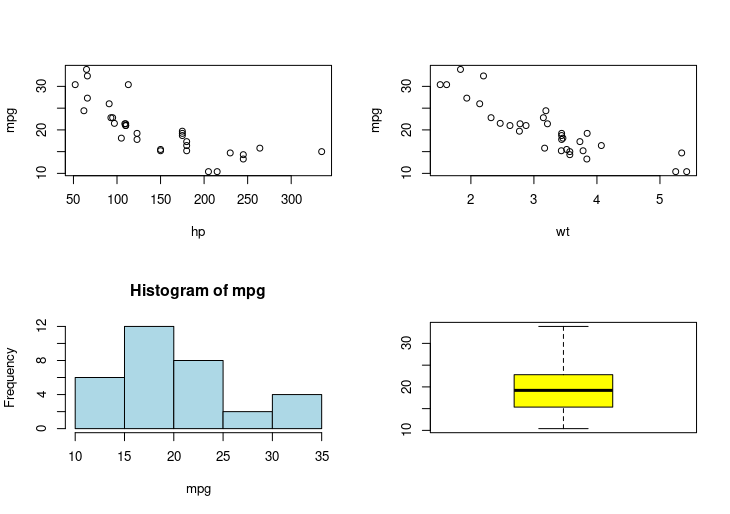
# HW5: Create a multi-plot layout (2x2 grid)
# HW6: Customize mpg vs. wt plot: title, axis labels, green points, gray background
# BASIC TASKS
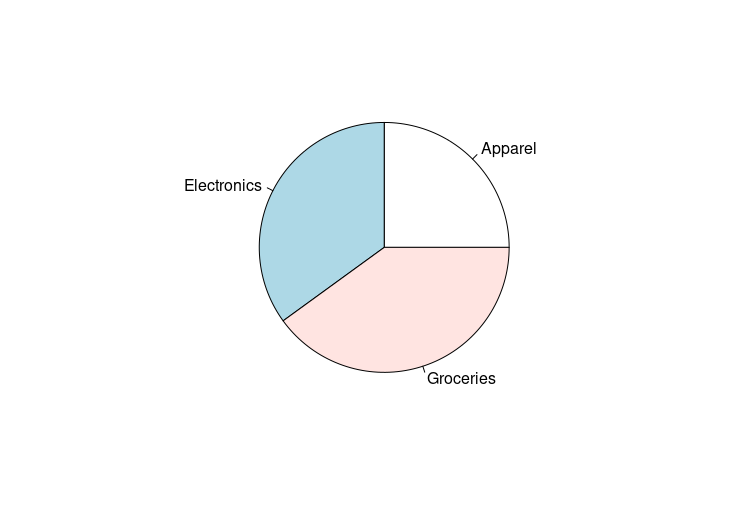
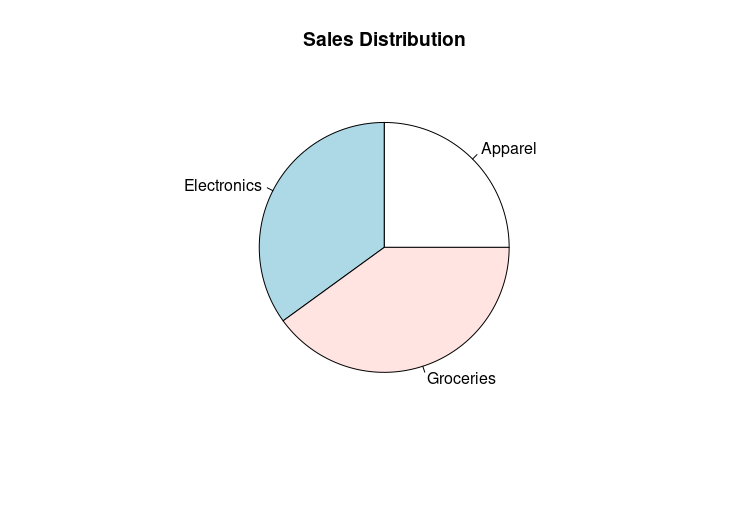
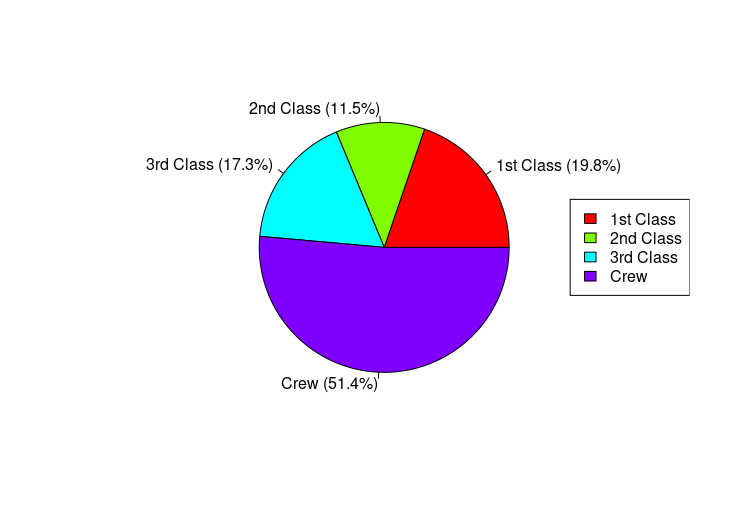
# HW1: Create a pie chart for sales data
# HW2: Add a title and explode the "Groceries" slice
# ADVANCED TASKS
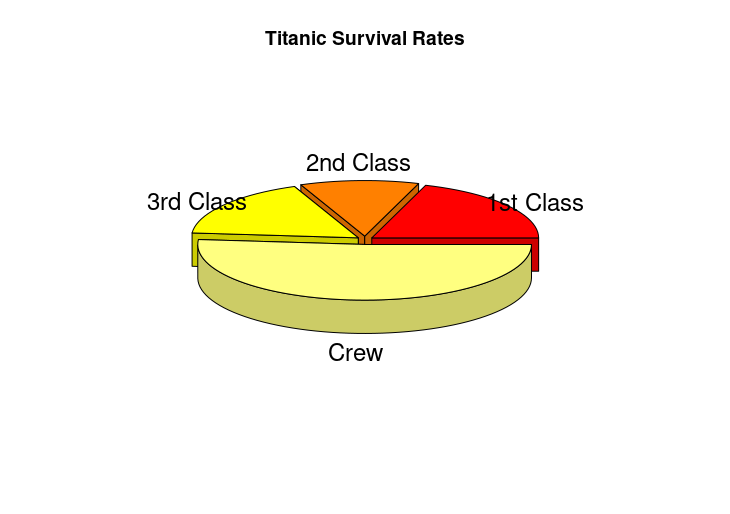
# HW3: Plot Titanic survival rates with gradient colors
# HW4: Add a legend and percentage labels
# HW5: Create a 3D pie chart (use plotrix package)
Vectors are 1D data structures holding elements of the same type .
Sort : sort() (ascending) or rev(sort()) (descending).
Create : Use c(), seq(from, to, by), or rep(value, times).
Access : Use [index] (positive/negative), logical vectors, or names.
Length : length(vector).
# HW1: Create a vector of even numbers 2, 4, 6 using `seq()`
# HW2: Access the 3rd element of `c(10, 20, 30, 40)`
# HW3: Sort `c(5, 1, 3)` in descending order
# HW4: Check the length of `c("a", "b", "c")`
# HW5: Create a vector with 3 copies of "R" using `rep()`
Add/Remove : list[[new_index]] <- value or list[index] <- NULL.
Create : list().
Access : [index] (returns sublist), [[index]] (returns element), or $name.
Modify : Assign new values via [[ ]] or append().
# HW1: Create a list with "apple", 25, and a sub-list `c(1, 2)`
# HW2: Access the sub-list `c(1, 2)` from HW1
# HW3: Change "apple" to "banana" in the list
# HW4: Add `TRUE` to the end of the list
# HW5: Remove the 2nd element (25)
# HW1: Create a 3x2 matrix with 1-6 using `matrix()`
# HW2: Extract the 2nd row
# HW3: Extract the 1st column
# HW4: Add a row `7, 8` to the matrix
# HW5: Create a matrix with 1, 2 repeated 3 times using `rep()`
Arrays extend matrices to multi-dimensional data .
Dimensions : dim() to check or set dimensions.
Create : array(data, dim=c(rows, cols, ...)).
Access : [i, j, k] for specific elements.
# HW1: Create a 2x2x2 array with values 1-8
# HW2: Access the 3rd element of the 1st layer
# HW3: Extract the 2nd layer (all rows/columns)
# HW4: Check the total length of the array
# HW5: Convert a vector `1:12` into a 3x4 array
Data frames store tabular data (mixed types allowed).
Modify : Add/remove columns via $ or [ ].
Create : data.frame().
Access : $column, [, "column"], or subset().
# HW1: Create a data frame with Name (Alice, Bob), Age (25, 30)
# HW2: Access the "Name" column using `$`
# HW3: Add a column "Salary" with 5000, 6000
# HW4: Remove the "Age" column
# HW5: Check the number of rows
Factors store categorical data with predefined levels.
Ordered Factors : ordered=TRUE for ranking.
Create : factor().
Modify Levels : levels(), factor(..., levels=).
# HW1: Create a factor with "Low", "Medium", "High"
# HW2: Check the levels of the factor
# HW3: Add "Very High" as a new level
# HW4: Remove "Medium" from the factor
# HW5: Convert the factor to an ordered factor
Use vectors (created with c()) to store multiple values of the same type.
# HW 1: Create a vector of numbers 1, 2, 3
# HW 2: Create a vector of colors: "red", "blue"
R
nums <-c(1, 2, 3) colors <-c("red", "blue")
5. To Define a Value
Assign values to variables using <- or =. Example: x <- 10.
# HW 1: Assign 3.14 to "pi"
# HW 2: Assign "Rocks" to "language"
R
pi<-3.14language <-"Rocks"
6. How to make a Comment
Use # to add comments (notes) to your code. R ignores these lines.
# HW 1: Write a comment explaining the next line
print("Learning R!")
R
# This line prints a motivational message print("Learning R!")
7. Variables and Their Types
Variables in R store data, and their type is automatically inferred from the assigned value. Use <- or = to assign values. Example: x <- 10 (numeric), y <- "Hello" (character).
# HW1: Assign 3.14 to a variable
# HW2: Assign "R Programming" to a variable
# HW3: Assign TRUE to a variable
R supports numeric (e.g., 10.5), integer (e.g., 55L), complex (e.g., 9+3i), character (e.g., "R is exciting"), and logical (e.g., TRUE). Use class() to check the type.
# HW1: Create a numeric variable with 787
# HW2: Create an integer with 100L
# HW3: Create a complex number 9+3i
# HW4: Create a character "FALSE"
# HW5: Create a logical FALSE
R
num <-787integer_val <-100Lcomplex_num <-9+3ichar <-"FALSE"logical_val <-FALSE
9. Simple Math Functions
R has built-in functions for math operations:
min(): Finds the smallest value.
floor(): Rounds down to the nearest integer.
max(): Finds the largest value.
sqrt(): Calculates the square root.
abs(): Returns absolute value.
ceiling(): Rounds up to the nearest integer.
# HW1: Find the minimum of 10, 20, 5
# HW2: Calculate the square root of 16
# HW3: Round 3.2 up and 4.9 down
# HW4: Get the absolute value of -7.5
Repeats code while a condition is TRUE. Use break to exit early.
# HW1: Print numbers 1 to 5
# HW2: Sum numbers from 1 to 3
R
# HW1 i <-1while (i <=5) { print(i) i <- i +1} # HW2 total <-0j <-1while (j <=3) { total <- total + j j <- j +1} print(total) # Output: 6
17. For Loop
Iterates over a sequence (like a vector). Use break/next to control flow.
# HW1: Print numbers 1 to 3 from c(1, 2, 3)
# HW2: Calculate sum of 1, 2, 3 using a loop
# HW3: Loop through a matrix (2x2) and print values
R
# HW1 for (num inc(1, 2, 3)) { print(num) } # HW2 sum <-0for (i in1:3) { sum <- sum + i } print(sum) # Output: 6 # HW3 mat <-matrix(1:4, nrow=2) for (row in1:nrow(mat)) { for (col in1:ncol(mat)) { print(mat[row, col]) } }
18. Functions
Reusable code blocks. Use function() to define, and return() to output results.
# HW1: Create a function to square a number
# HW2: Create a function that says "Hello, [name]!"
Course Review: How to Write and Publish a Scientific Paper
Recently, I completed the Coursera course “How to Write and Publish a Scientific Paper.” As someone new to research, I found this course incredibly valuable for building a strong foundation. It breaks down the research process step by step, from understanding the basics to confidently preparing your work for publication.
The course covers essential topics like structuring your paper, choosing the right journal, and navigating the peer-review process. What stood out most to me was how beginner-friendly yet comprehensive the lessons were—perfect for anyone starting their research journey.
If you’re looking to demystify academic writing and take your first step into the world of publishing, I highly recommend this course.
This project-centered course is meticulously designed to lead students through the entire process of writing and publishing a scientific paper. It encompasses:
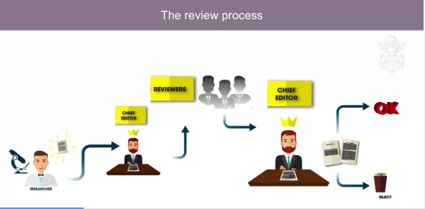
Understanding Academia: Provides insights into the academic publishing landscape, including how scientific journals operate and the ethical considerations involved.
Delimiting Your Scientific Paper: Guides on defining the scope and structure of your paper, ensuring clarity and focus.
Writing the Paper: Offers practical advice on crafting each section of the manuscript, from the introduction to the conclusion, and emphasizes the importance of proper citation practices.
Post-Writing Checklist: Equips students with a comprehensive checklist to self-assess their work before submission, enhancing the likelihood of acceptance.
Personal Experience
As a novice in the research domain, I found this course to be exceptionally beneficial. The step-by-step approach demystified the complexities of scientific writing. The emphasis on ethical considerations and the peer-review process provided a holistic understanding of academic publishing. The practical assignments, particularly outlining a complete scientific paper and selecting an appropriate journal for submission, were instrumental in reinforcing the concepts learned.
Here are some interesting screenshots of the course that you might find interesting ;